SlotLifter: Slot-guided Feature Lifting for Learning Object-centric Radiance Fields
✶ indicates equal contribution
1State Key Laboratory of General Artificial Intelligence, BIGAI
2Tsinghua University
ECCV 2024
Abstract
The ability to distill object-centric abstractions from intricate visual scenes underpins human-level generalization. Despite the significant progress in object-centric learning methods, learning object-centric representations in the 3D physical world remains a crucial challenge. In this work, we propose SlotLifter, a novel object-centric radiance model that aims to address the challenges of scene reconstruction and decomposition via slot-guided feature lifting. Such a design unites object-centric learning representations and image-based rendering methods, offering state-of-the-art performance in scene decom-position and novel-view synthesis on four challenging synthetic and four complex real-world datasets, outperforming existing 3D object-centric learning methods by a large margin. Through extensive ablative studies, we showcase the efficacy of each design in SlotLifter, shedding light on key insights for potential future directions.
Overview of SlotLifter
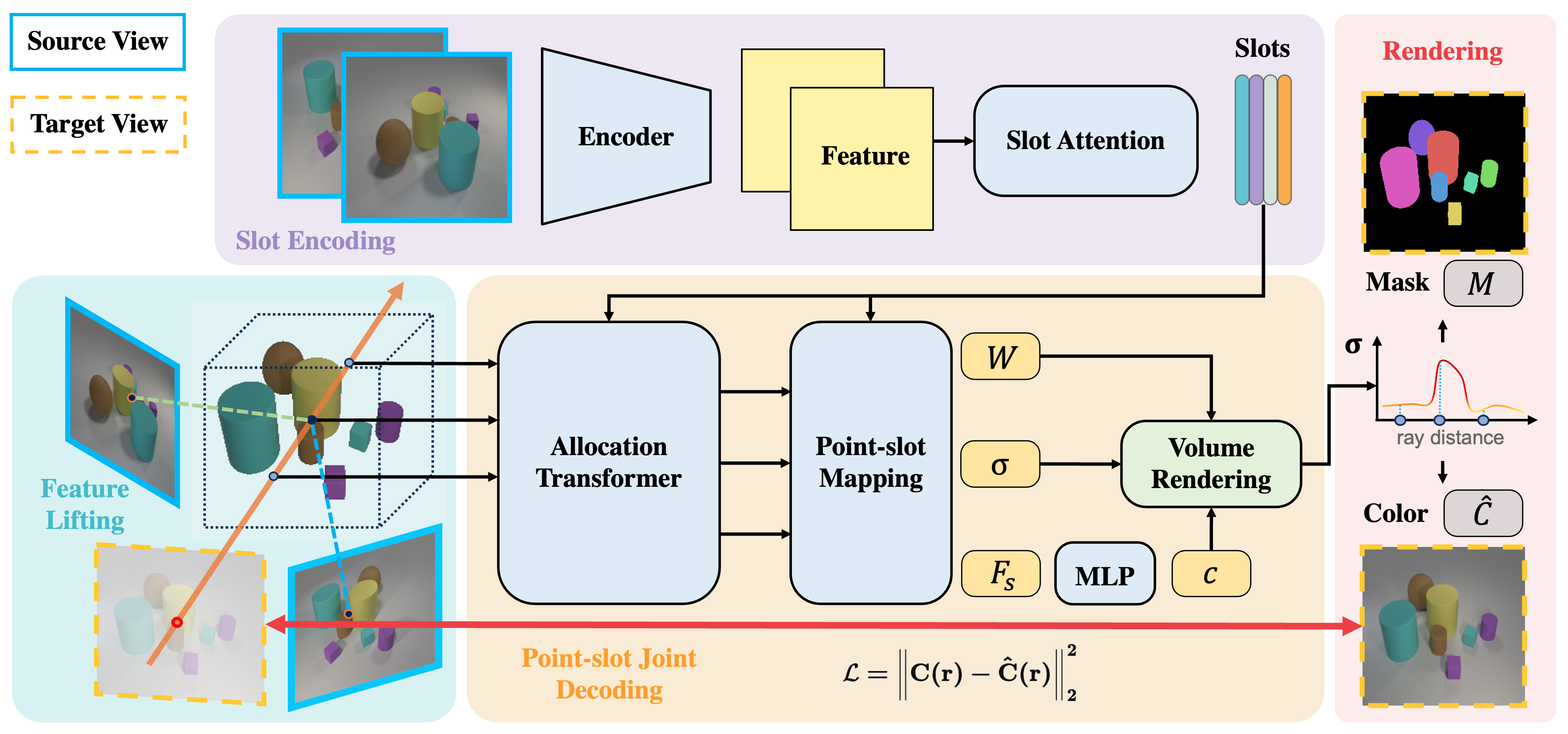
SlotLifter extracts slots from input source views during the slot encoding process. It then lifts 2D feature maps of input views to initialize 3D point features. These point features are inputted into an allocation Transformer as queries to attend slots for point-slot joint decoding. Then we obtain the point-slot mapping \(W_p\), density \(\sigma\), and the slot-aggregated point feature \(F_s\) via an attention layer. Finally, SlotLifter renders the novel-view image and segmentation masks with point colors and point-slot mappings through volume rendering.
Distinctions with Previous Methods
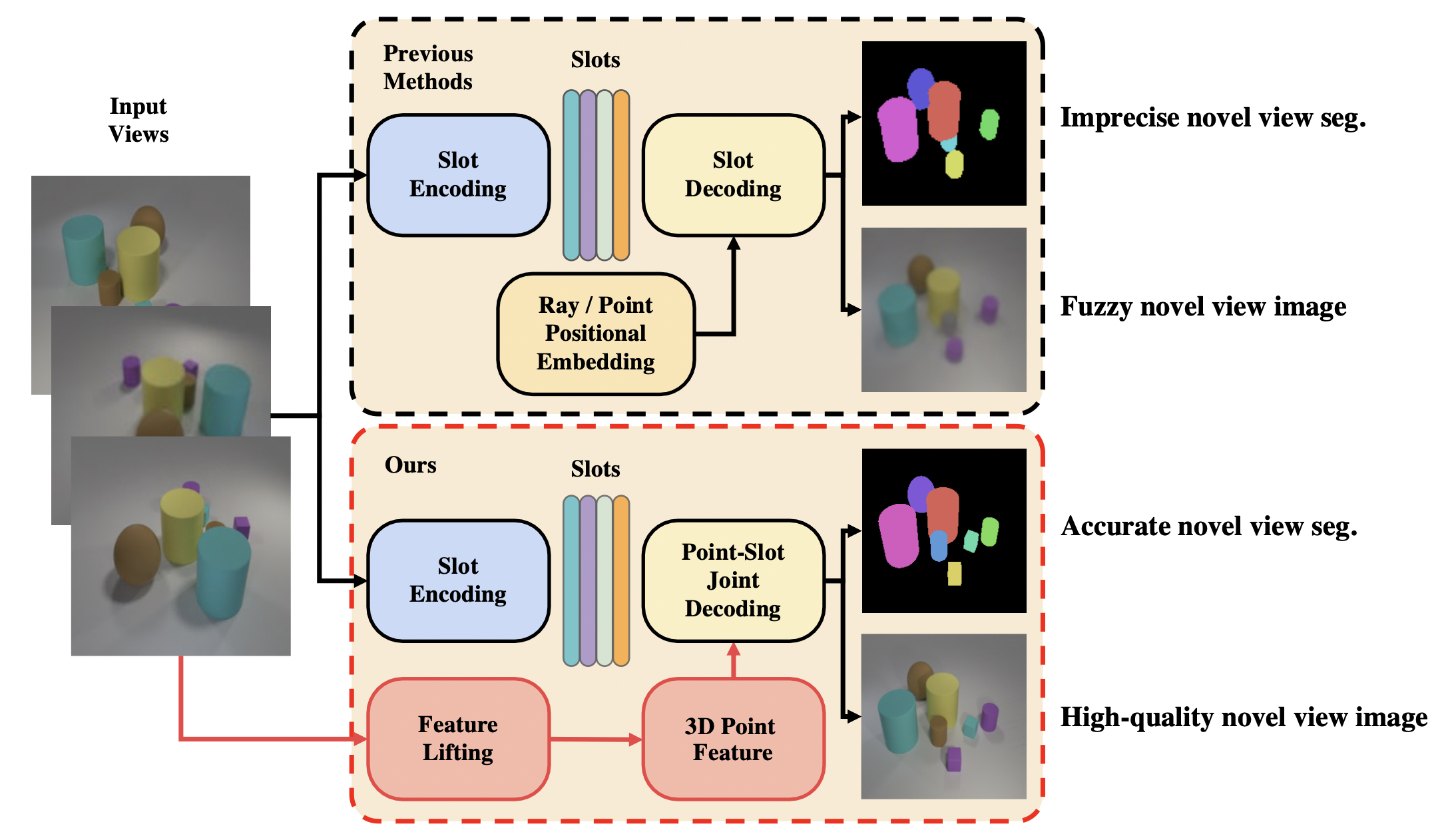
Previous methods render novel views by decoding slots with positional embedding of rays or points, resulting in fuzzy images and imprecise segmentation masks due to the information loss during slot encoding. In contrast, we propose to lift 2D multi-view image features to initialize 3D point features, rendering high-quality novel-view images and masks through point-slot joint decoding.
Introduction of SlotLifter
Results on ScanNet
We show the results of SlotLifter on ScanNet datasets. Click the button to select a scene for result visualization.




Results on Kitchen-Matte & Kitchen-Shiny
We show the results of SlotLifter on Kitchen-Matte and Kitchen-Shiny datasets. The first column shows the input image, the second column shows the reconstructed 3D scenes by SlotLifter, and the third column shows the segmentation masks by SlotLifter. Click the button to select a scene for result visualization.


















Results on Synthetic 3D scenes
We show the results of SlotLifter on synthetic datasets. Click the button to select a scene for result visualization.


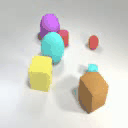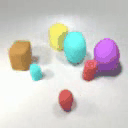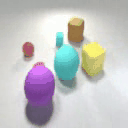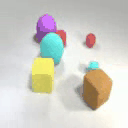
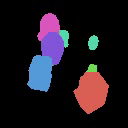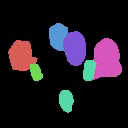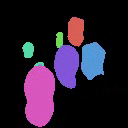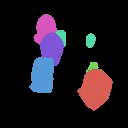
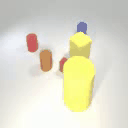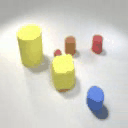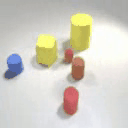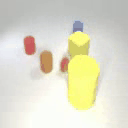
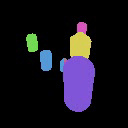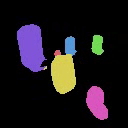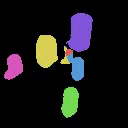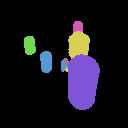

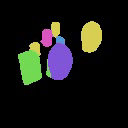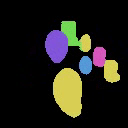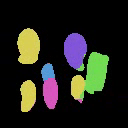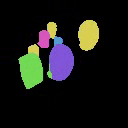











Bibtex
If you find our project useful, please consider citing us:
@inproceedings{liu2024slotlifter,
title={SlotLifter: Slot-guided Feature Lifting for Learning Object-centric Radiance Fields},
author={Liu, Yu and Jia, Baoxiong and Chen, Yixin and Huang, Siyuan},
booktitle={European Conference on Computer Vision (ECCV)},
year={2024}
}